Abstract
Recent progress in artificial intelligence has been strongly shaped by vertical scaling: increasing model size, training data, and compute budgets to produce more capable foundation models. However, many practical AI systems now improve performance through a different path: horizontal scaling. Horizontal scaling increases system capability by composing models with external memory, retrieval systems, tools, evaluators, specialized agents, and orchestration pipelines. This paper defines horizontal scaling in AI systems, compares it with traditional vertical scaling, and proposes a taxonomy for understanding modular AI architectures. Representative examples include (RAG) retrieval-augmented generation, tool-using language models, reasoning-and-acting agents, multi-agent systems, and personalized knowledge graphs. The central argument is that horizontal scaling offers a compute-efficient path for independent researchers, small teams, and edge-deployment environments, because it shifts progress from raw parameter growth to system design. At the same time, horizontal systems introduce new risks involving orchestration complexity, latency, coordination errors, data fragmentation, and evaluation difficulty. The most promising future is not purely vertical or purely horizontal, but hybrid: strong foundation models supported by modular systems that extend memory, action, verification, personalization, and governance.
1. Introduction
The dominant story of modern artificial intelligence has been the story of scaling larger models, larger datasets, and larger training runs. We have produced major gains in code generation, reasoning and instruction following. This path can be described as vertical scaling: increasing the capability of an AI system primarily by increasing the parameters, size and compute intensity of the model itself (Brown et al., 2020; Kaplan et al., 2020).
Vertical scaling has produced impressive results, but it also creates a major barrier. Frontier model training requires enormous compute budgets, specialized hardware, large engineering teams, and access to massive datasets. For independent researchers, students, small laboratories, and developers working with consumer hardware, this path is often inaccessible. The question then becomes: how can AI capability be improved when direct access to frontier-scale compute is unavailable?
One answer is horizontal scaling. In this paper, horizontal scaling refers to the practice of increasing AI system capability by distributing intelligence across multiple modules. Instead of forcing one model to memorize everything, an agent may retrieve information from a knowledge base, call tools, interact with code, query databases and much more.
This reframes progress in AI. Capability does not only come from making a model larger. It can also come from designing better systems around a model. For compute-constrained builders, this matters because it creates a realistic path to useful AI research and development without training a frontier model from scratch. Horizontal scaling turns the problem from “How do I build a bigger brain?” into “How do I connect smaller abilities into a stronger system?”
This is the core claim of the paper: horizontal scaling gives low-resource builders a way to increase AI capability through architecture, orchestration, memory, and verification instead of only through model size. It does not argue that bigger models are useless. It argues that useful intelligence can also be built by connecting smaller abilities together.
This paper makes three contributions. First, it defines horizontal scaling and contrasts it with vertical scaling. Second, it proposes a taxonomy of horizontal scaling methods, including memory scaling, tool scaling, agent scaling, modality scaling, evaluation scaling, personalization scaling, and governance scaling. Third, it argues that horizontal scaling is especially important for democratizing AI development because it allows low-resource builders to create capable systems through architecture, orchestration, and knowledge organization.
2. Defining Vertical and Horizontal Scaling
Vertical scaling is the traditional scale-up path. In AI, it includes increasing model parameters, training data, training compute, context length, fine-tuning budget, or hardware capacity. The goal is to make the core model itself more capable. A vertically scaled system relies heavily on the internal capacity of a model to store knowledge, generalize across tasks, and produce correct outputs.
Horizontal scaling is the scale-out path. It improves capability by connecting a model to external systems. These systems may include retrieval indexes, databases, calculators, search engines, code interpreters, software APIs, memory stores, validation gates, specialist models, or multiple agents. The goal is not necessarily to make the core model larger, but to reduce the burden placed on the model by giving it structured access to outside capabilities.
A simple example are RAG systems. A language model like GPT alone must answer using its internal training data and prompt context. A RAG can search a dedicated knowledge store, retrieve relevant documents, and use those documents to answer more accurately. The model is not necessarily larger, but the system is more capable because memory has been moved outside the model (Lewis et al., 2020).
Another example is tool use. A model may be weak at exact arithmetic, current information, file operations, or code execution. Instead of training a larger model to solve all of these internally, a horizontal system can give the model access to calculators, browsers, compilers, databases, or APIs. The model becomes a coordinator rather than the only source of intelligence (Schick et al., 2023).
The distinction can be summarized as follows: vertical scaling increases the power of the model; horizontal scaling increases the power of the system.
Figure 1. Conceptual difference between vertical and horizontal scaling
Vertical Scaling
Larger model
More data
More parameters
More compute
↓
One stronger model
Horizontal Scaling
Model
↓
┌───────┼────────┬──────────┬──────────┐
↓ ↓ ↓ ↓ ↓
Memory Tools Agents Evaluators Governance
↓ ↓ ↓ ↓ ↓
One stronger system
Figure 1. Vertical scaling concentrates capability inside the model itself. Horizontal scaling distributes capability across memory, tools, agents, evaluators, and governance layers.
3. A Taxonomy of Horizontal Scaling
Horizontal scaling is not one technique. It is a family of system-design strategies. This section proposes seven categories.
3.1 Memory Scaling
Memory scaling extends a model with external knowledge. This includes RAGS, GraphRAG, vector databases, long-term memory, personal knowledge bases, and structured knowledge graphs. Instead of expecting a model to contain all relevant knowledge inside its parameters, the system retrieves information from a maintained source.
Memory scaling is especially useful for domains where knowledge changes over time or where the relevant information is private. A personal research vault, company documentation system, or local Obsidian knowledge graph can function as memory that grows independently of the model.
3.2 Tool Scaling
Tool scaling gives models access to external actions. Tools may include calculators, search engines, browsers, code execution environments, file systems, APIs, databases, shell commands, and specialized software. The model does not need to perform every operation internally. It can decide when to call a tool, pass arguments, observe results, and continue reasoning from the output.
This approach turns the model into a controller. Its intelligence is expressed through tool selection, planning, interpretation, and error recovery.
3.3 Agent Scaling
Agent scaling divides work across multiple roles. A system may include a planner, executor, critic, verifier, researcher, summarizer, coder, or domain specialist. Each agent has a narrower job than the full task. This can reduce complexity because each module handles a limited part of the reasoning process.
However, agent scaling also increases coordination difficulty. Agents may disagree, duplicate work, misunderstand context, or create long chains of error. This makes logging, evaluation, and role design important.
3.4 Modality Scaling
Modality scaling routes different types of information to different systems. A language model may call a vision model for images, an audio model for speech, a code model for programming tasks, a mathematical engine for symbolic reasoning, or a document parser for PDFs. This allows the system to handle multimodal tasks without requiring one model to be equally strong across every modality.
3.5 Evaluation Scaling
Evaluation scaling adds validators, tests, benchmark harnesses, critics, static analyzers, unit tests, grading scripts, or verification steps. The purpose is to reduce blind trust in model output. In a horizontal system, generation and evaluation can be separated. One module proposes an answer, while another checks it.
This is important because modular systems can fail in many places. Evaluation scaling makes those failures more visible.
3.6 Personalization Scaling
Personalization scaling adapts an AI system to a specific user, project, organization, or workflow. This can include user-specific memory, local knowledge graphs, private notes, preference models, project histories, and personalized learning paths. Instead of training a global model to understand every individual deeply, a horizontal system can attach private context to a general model.
This is one of the strongest arguments for horizontal scaling. It allows personalization without requiring users to send all private data into a central training process.
3.7 Governance Scaling
Governance scaling adds logs, provenance, permission tiers, audit trails, quarantine systems, approval gates, and privacy scopes. As AI systems become more agentic, governance cannot only happen at the final output. It must happen throughout the pipeline.
A horizontally scaled system can record which source was retrieved, which tool was called, which agent made a decision, which validator approved it, and which claims were quarantined. This creates an audit trail that is often missing from monolithic model outputs.
4. Comparing Vertical and Horizontal Scaling
Vertical and horizontal scaling solve different problems. Vertical scaling can improve general ability, fluency, transfer learning, and raw performance across tasks. A larger and better-trained model may require less scaffolding and may generalize more effectively to unfamiliar problems. But vertical scaling is expensive, centralized, and often opaque.
Horizontal scaling can be more accessible. It allows smaller models to perform better by giving them external memory, tools, and structured workflows. It also allows systems to be updated without retraining the model. A retrieval index can be refreshed, a tool can be replaced, a verifier can be improved, or a new agent can be added.
The trade-off is complexity. A vertical system may fail because the model gives a wrong answer for unclear reasons. A horizontal system may fail because the retriever found bad documents, the tool call was malformed, the planner decomposed the task poorly, the verifier missed an error, or the orchestration layer passed the wrong context. Horizontal systems are more inspectable, but they also have more moving parts.
In cost terms, vertical scaling tends to move cost into training and serving large models. Horizontal scaling moves cost into engineering, integration, testing, orchestration, and maintenance. For small builders, this trade may be favorable because engineering effort is more accessible than frontier-scale GPU clusters.
In transparency terms, horizontal systems have an advantage. Retrieval citations, tool logs, agent traces, and validation results can be inspected. This does not make the system automatically safe or correct, but it provides more places for debugging and governance.
In privacy terms, horizontal scaling can also be stronger. A user can keep a local knowledge base, private graph, or restricted memory store while using a general model as an interface. This allows personal context to remain outside the model provider’s training process.
The important point is that horizontal scaling does not need to beat vertical scaling at everything to matter. It only needs to create another path. For people without frontier compute, that path may be the difference between only consuming AI and actually building useful AI systems.
Table 1. Vertical versus horizontal scaling
| Attribute | Vertical Scaling | Horizontal Scaling |
|---|---|---|
| Core method | Increase model size, training data, and compute | Compose models with memory, tools, agents, evaluators, and governance |
| Main bottleneck | Hardware, data, and training budget | Engineering, orchestration, and evaluation |
| Update path | Retrain, fine-tune, increase context, or use a larger model | Update the knowledge base, add tools, improve agents, replace modules |
| Transparency | Often low because the model is a single black box | Higher because retrieval, tool calls, logs, and validation can be inspected |
| Personalization | Hard unless fine-tuned or given long context | Easier through local memory, personal graphs, and private stores |
| Failure mode | One model gives a wrong answer for unclear reasons | A component fails, retrieves bad data, misroutes context, or breaks coordination |
| Low-resource accessibility | Low for frontier training | Higher because builders can scale through system design |
5. Risks and Limitations
Horizontal scaling introduces several limitations.
First, it increases engineering complexity. Building a pipeline with retrieval, tools, agents, validators, memory, and privacy rules requires system design beyond prompt writing. Debugging can become difficult because errors may originate in any component.
Second, horizontal systems can increase latency. Retrieval, tool calls, validation, and multi-agent coordination all take time. Some steps can run in parallel, but poorly designed pipelines may become slow.
Third, modular systems can suffer from coordination errors. A retriever may return irrelevant documents. A planner may break a task into the wrong subtasks. A tool may produce unexpected output. A verifier may check the wrong property. These failures can compound.
Fourth, horizontal systems can have coverage gaps. If the system lacks a needed tool, source, skill, or specialist module, the whole pipeline may fail. This is different from vertical scaling, where the model may still attempt the task from general knowledge.
Fifth, managing many sources creates data fragmentation. Knowledge bases, vector indexes, APIs, local files, agent memories, and logs must be synchronized and governed.
Sixth, evaluation becomes harder. It is not enough to ask whether the final answer is correct. We must also ask which component caused a failure and whether the system can recover.
Finally, horizontal systems introduce new security and manipulation risks. A poisoned knowledge base, malicious tool output, compromised plugin, or misleading retrieval result can influence the model. This means horizontal systems require provenance tracking, trust boundaries, and validation gates.
These risks do not weaken the core claim. They define the engineering challenge. If horizontal scaling is the low-resource path to stronger systems, then orchestration, evaluation, and governance become part of the research frontier.
6. Case Study: A Personalized Knowledge Graph as Horizontal Scaling
One practical example of horizontal scaling is a personal AI knowledge system. In this architecture, a language model is connected to a user’s local knowledge base, conversation archive, project notes, source documents, and visual graph. The model does not need to remember everything internally. Instead, it reads, writes, retrieves, summarizes, links, and updates external memory.
Such a system may include several modules. A raw capture layer stores conversations, documents, and notes. A mining layer extracts concepts, skills, goals, questions, decisions, and patterns. A privacy layer separates public system concepts from local private memory and restricted notes. A graph builder turns these nodes into a knowledge graph. A visualizer displays the graph as a cognitive map. A stewarding layer updates the graph over time.
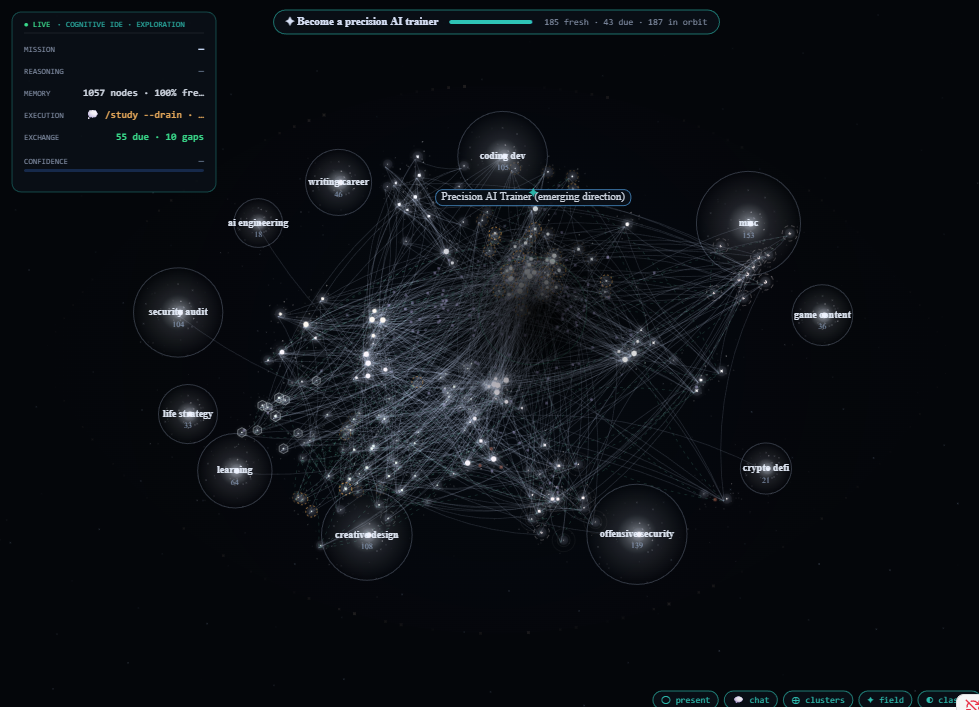
Figure 2. The visual graph represents a local cognitive map made from accumulated conversations, projects, skills, goals, gaps, and learning signals. This figure shows horizontal scaling applied to personal learning: instead of relying on a model to remember everything internally, the system externalizes memory into a graph that can be inspected, expanded, and used for future reasoning.
Figure 3. Personalized horizontal-scaling pipeline
Conversations, notes, documents, projects
↓
Raw capture
↓
Mining and claim extraction
↓
Privacy and scope classification
↓
Knowledge graph construction
↓
Cognitive Lens visualization
↓
Learning frontier and next actions
Figure 3. The system distributes cognition across capture, extraction, classification, graph construction, visualization, and planning. Each layer performs a specialized role so that the model does not need to hold every memory, decision, or learning path internally.
This is horizontal scaling applied to learning. The user’s intelligence is extended not by training a new frontier model, but by building a modular system that remembers, organizes, evaluates, and visualizes knowledge. The system becomes more useful as it accumulates structured context.
This case also shows why governance matters. A personal graph may contain public concepts, private notes, sensitive memories, and restricted strategy. A safe system must distinguish between local graph use and public export. It should be able to graph everything locally while sharing only generalized architecture, logic, and concepts.
The case study reinforces the core claim of the paper: horizontal scaling is not only a production architecture. It can also be a learning architecture. It gives independent builders a way to turn conversations, notes, tools, and personal knowledge into a system that compounds over time.
7. Proposed Evaluation Method
A future empirical study could compare several system configurations.
The baseline would be a language model answering from the prompt alone. The second condition would add retrieval. The third would add retrieval and tool use. The fourth would add retrieval, tools, and a verifier. The fifth would add a personalized knowledge graph and long-term memory.
Tasks could include factual recall, project-memory questions, coding tasks, research synthesis, and learning-path generation. Metrics could include accuracy, citation quality, latency, cost, user usefulness, privacy exposure, and failure attribution.
This kind of evaluation would help map the trade-off frontier between vertical and horizontal scaling. It would show when system composition helps, when it adds unnecessary overhead, and which components produce the largest gains.
8. Discussion
Horizontal scaling should not be viewed as a replacement for vertical scaling. Larger models remain powerful because they provide broad generalization, stronger language understanding, and better task transfer. But horizontal scaling changes who can participate in AI development. It allows independent builders and small teams to create useful systems without training frontier models.
The future is likely hybrid. Strong foundation models will serve as flexible reasoning and language interfaces. Around them, modular systems will provide memory, tools, agents, verification, personalization, and governance. The most capable systems may not be the largest models alone, but the best-composed systems. This matches the broader shift toward compound AI systems, where model calls are combined with tools, retrieval, control logic, and other components (Berkeley Artificial Intelligence Research, 2024).
This has important implications for AI research. Researchers should study not only scaling laws for model size and compute, but also composition laws for modular systems. We need better ways to measure how retrieval quality, tool reliability, agent coordination, memory structure, and verification steps affect total system performance.
For compute-constrained builders, this is where the opportunity is. If the largest labs own the vertical scaling frontier, independent builders can still explore the composition frontier. They can ask what happens when a model is connected to the right memory, the right tools, the right checks, and the right personal knowledge structure.
9. Conclusion
Vertical scaling and horizontal scaling represent two complementary paths for advancing AI. Vertical scaling increases capability by making models larger and more compute-intensive. Horizontal scaling increases capability by composing models with external systems that provide memory, tools, verification, specialization, personalization, and governance.
For compute-constrained researchers, horizontal scaling is especially important. It provides a path to meaningful AI development through architecture rather than raw hardware. It allows smaller systems to become more capable by distributing intelligence across modules.
However, horizontal scaling is not free. It introduces complexity, latency, coordination errors, evaluation challenges, and new attack surfaces. These risks must be managed through careful design, logging, provenance, privacy scopes, and validation.
The central lesson is that future AI progress will not be defined only by bigger models. It will also be defined by better systems. The frontier is not only the scaling law frontier, but also the composition frontier: how models, tools, memories, agents, and evaluators can be assembled into reliable, personal, transparent, and useful intelligence systems.
The core claim is simple: if vertical scaling asks how far intelligence can go by making models bigger, horizontal scaling asks how far intelligence can go by making systems better. For builders without frontier hardware, that second question may be the more important one.
References
Berkeley Artificial Intelligence Research. (2024). The Shift from Models to Compound AI Systems. BAIR Blog.
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., et al. (2020). Language Models are Few-Shot Learners. Advances in Neural Information Processing Systems.
Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., et al. (2022). Training Compute-Optimal Large Language Models. arXiv.
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., et al. (2020). Scaling Laws for Neural Language Models. arXiv.
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Advances in Neural Information Processing Systems.
Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Hambro, E., et al. (2023). Toolformer: Language Models Can Teach Themselves to Use Tools. arXiv.
Shen, Y., Song, K., Tan, X., Li, D., Lu, W., and Zhuang, Y. (2023). HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face. arXiv.
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., and Cao, Y. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. arXiv.
──────────────────────────────────── -- end of file ────────────────────────────────────